第8讲 调试理论与实践
本节课回答的问题:如何应对bug
调试理论
软件的两层含义
- 人类需求在信息世界的投影
- 计算过程的精确(数学)描述
调试困难的根本原因
因为bug的触发经历了漫长的过程。这个过程中,软件的状态发生了很多变化,而我们只能看到最后的结果。无法预知bug在哪里
单步调试,判断每一次状态,二分查找error的状态
- 调试DP题/图论算法如何判断状态呢?人脑不够用了
工具
- printf 打印log,快速定位
- gdb 精确定位,查看所有状态 看起来今天的主要内容是很工程的,讲了许多例子,都不是很懂,写完lab1再回来看吧
一切皆可调试
ssh -vvv 打印日志
gcc -v
make -n
这里推荐了musl libc
永远假设自己不是圣人,不能一次写出对的代码
防御性编程 加断言
例子:
平衡树的左旋
加assert()判断结点旋转的结果对不对

检查是否在堆区
assert(IN_RAGE(heap))
assert(0<=pid&&pid<=1000)
并发bug死锁
AA-Deadlock
假设你的 spinlock 不小心发生了中断
- 在不该打开中断的时候开了中断
- 在不该切换的时候执行了
yield()
|
|
ABBA-Deadlock
|
|
上锁的顺序很重要……
-
1swap本身看起来没有问题
swap(1, 2);swap(2, 3),swap(3, 1)→ 死锁
|
|
避免死锁
死锁产生的四个必要条件 (Edward G. Coffman, 1971):
- 互斥:一个资源每次只能被一个进程使用
- 请求与保持:一个进程请求资阻塞时,不释放已获得的资源
- 不剥夺:进程已获得的资源不能强行剥夺
- 循环等待:若干进程之间形成头尾相接的循环等待资源关系
“理解了死锁的原因,尤其是产生死锁的四个必要条件,就可以最大可能地避免、预防和解除死锁。所以,在系统设计、进程调度等方面注意如何不让这四个必要条件成立,如何确定资源的合理分配算法,避免进程永久占据系统资源。此外,也要防止进程在处于等待状态的情况下占用资源。因此,对资源的分配要给予合理的规划。” ——Bullshit.
按照规定的顺序获得锁
数据竞争
不同的线程同时访问同一段内存,且至少有一个是写。
-
两个内存访问在 “赛跑”,“跑赢” 的操作先执行
-
- peterson-barrier.c
-
内存访问都在赛跑
- MFENCE:
如何留下最少的 fence,依然保证算法正确?
-
数据竞争 (cont’d)
Peterson 算法告诉大家:
- 你们写不对无锁的并发程序
- 所以事情反而简单了
用互斥锁保护好共享数据
消灭一切数据竞争
数据竞争:例子
以下代码概括了你们遇到数据竞争的大部分情况
- 不要笑,你们的 bug 几乎都是这两种情况的变种
|
|
|
|
class: center, middle
更多类型的并发 Bug
程序员:花式犯错
回顾我们实现并发控制的工具
- 互斥锁 (lock/unlock) - 原子性
- 条件变量 (wait/signal) - 同步
忘记上锁——原子性违反 (Atomicity Violation, AV)
忘记同步——顺序违反 (Order Violation, OV)
Empirical study: 在 105 个并发 bug 中 (non-deadlock/deadlock)
- MySQL (14/9), Apache (13/4), Mozilla (41/16), OpenOffice (6/2)
- 97% 的非死锁并发 bug 都是 AV 或 OV。
原子性违反 (AV)
“ABA”
- 我以为一段代码没啥事呢,但被人强势插入了

原子性违反 (cont’d)
有时候上锁也不解决问题
- “TOCTTOU” - time of check to time of use
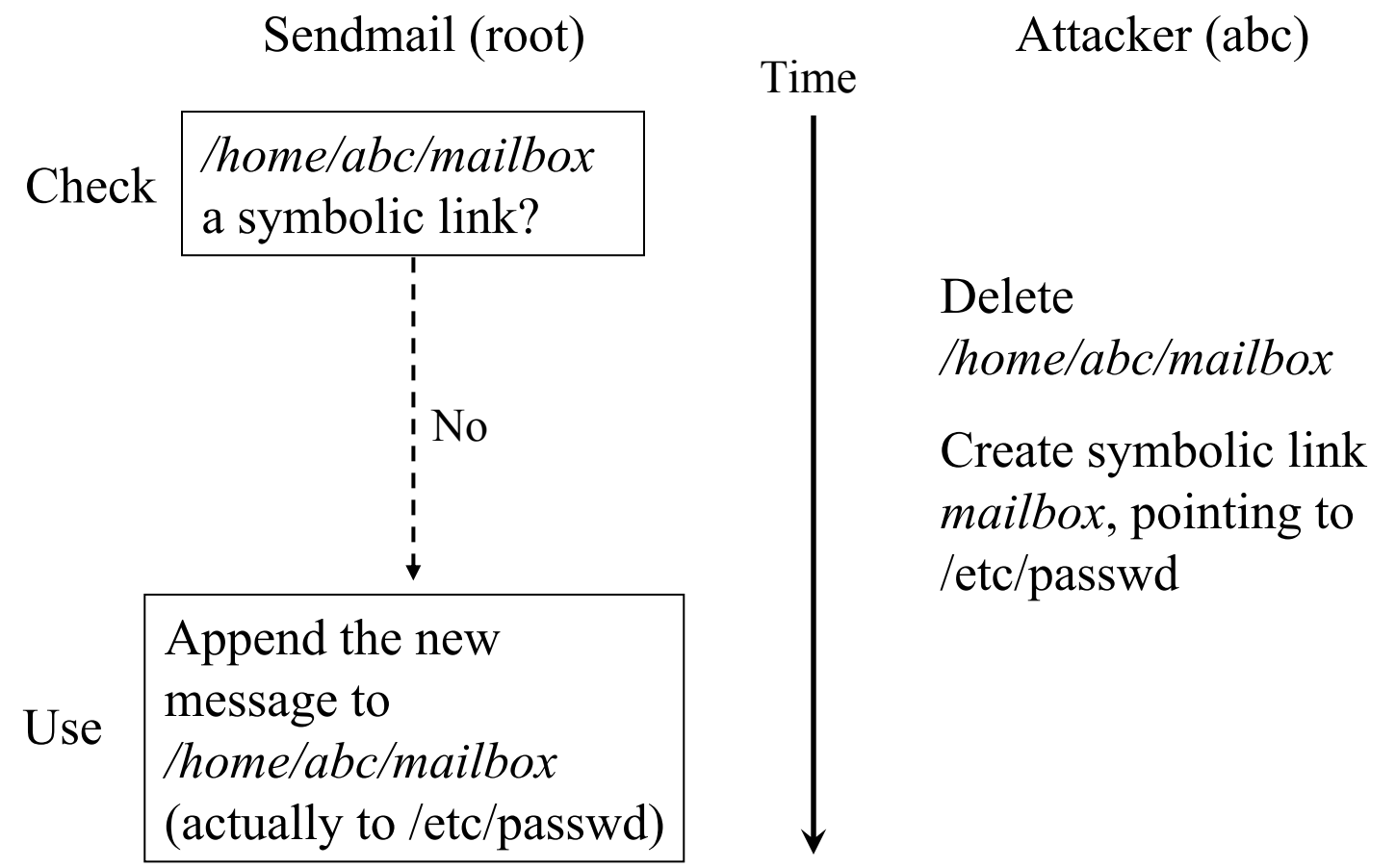
顺序违反 (OV)
“BA”
- 怎么就没按我预想的顺序来呢?
- 例子:concurrent use after free

class: center, middle
应对并发 Bug 的方法
完全一样的基本思路:否定你自己
还是得始终假设自己的代码是错的。
然后呢?
- 做好测试
- 检查哪里错了
- 再检查哪里错了
- 再再检查哪里错了
- (把任何你认为 “不对” 的情况都检查一遍)
例如:用 lock ordering 彻底避免死锁?
- 你想多了:并发那么复杂,程序员哪能充分测试啊
Lockdep: 运行时的死锁检查
Lockdep 规约 (Specification)
- 为每一个锁确定唯一的 “allocation site”
- lock-site.c
- assert: 同一个 allocation site 的锁存在全局唯一的上锁顺序
检查方法:printf
- 记录所有观察到的上锁顺序,例如[x,y,z]⇒x→y,x→z,y→z
- 检查是否存在 x⇝y∧y⇝x
- Since Linux Kernel 2.6.17, also in OpenHarmony!
ThreadSanitizer: 运行时的数据竞争检查
为所有事件建立 happens-before 关系图
-
Program-order + release-acquire
-
对于发生在不同线程且至少有一个是写的
x,y
检查
x≺y∨y≺x
更多的检查:动态程序分析
在事件发生时记录
- Lockdep: lock/unlock
- ThreadSanitizer: 内存访问 + lock/unlock
解析记录检查问题
- Lockdep: x⇝y∧y⇝x
- ThreadSanitizer: x⊀y∧y⊀x
付出的代价和权衡
- 程序执行变慢
- 但更容易找到 bug (因此在测试环境中常用)
动态分析工具:Sanitizers
没用过 lint/sanitizers?
-
AddressSanitizer
(asan);
- (paper)
-
非法内存访问
-
ThreadSanitizer
(tsan): 数据竞争
- Demo: fish.c, sum.c, peterson-barrier.c; ktsan
-
MemorySanitizer (msan): 未初始化的读取
-
UBSanitizer
(ubsan): undefined behavior
- Misaligned pointer, signed integer overflow, …
- Kernel 会带着
-fwrapv编译
class: center, middle
这不就是防御性编程吗?
只不过不需要我亲自动手把代码改得乱七八糟了……
我们也可以!Buffer Overrun 检查
Canary (金丝雀) 对一氧化碳非常敏感
- 用生命预警矿井下的瓦斯泄露 (since 1911)

计算机系统中的 canary
- “牺牲” 一些内存单元,来预警 memory error 的发生
- (程序运行时没有动物受到实质的伤害)
Canary 的例子:保护栈空间 (M2/L2)
|
|
烫烫烫、屯屯屯和葺葺葺

msvc 中 debug mode 的 guard/fence/canary
- 未初始化栈:
0xcccccccc - 未初始化堆:
0xcdcdcdcd - 对象头尾:
0xfdfdfdfd - 已回收内存:
0xdddddddd
|
|
手持两把锟斤拷,口中疾呼烫烫烫
脚踏千朵屯屯屯,笑看万物锘锘锘
(它们一直在无形中保护你)
防御性编程:低配版 Lockdep
不必大费周章记录什么上锁顺序
- 统计当前的 spin count
- 如果超过某个明显不正常的数值 (1,000,000,000) 就报告
|
|
- 配合调试器和线程 backtrace 一秒诊断死锁
防御性编程:低配版 Sanitizer (L1)
内存分配要求:已分配内存 S=[ℓ0,r0)∪[ℓ1,r1)∪…
-
kalloc(
s
) 返回的
[ℓ,r)
必须满足
[ℓ,r)∩S=∅
- thread-local allocation + 并发的 free 还蛮容易弄错的
|
|
class: center, middle
总结
总结
本次课回答的问题
- Q: 如何拯救人类不擅长的并发编程?
Take-away message
- 常见的并发 bug
- 死锁、数据竞争、原子性/顺序违反
- 不要盲目相信自己:检查、检查、检查
- 防御性编程:检查
- 动态分析:打印 + 检查
class: center, middle