第一章 量化设计与分析基础
1.1 引言
86年以前:性能增长主要依赖实现技术的进步
03年以前,性能增长除了依赖技术的进步以外,还依赖系统结构的革新(RISC,指令级并行ILP与cache)
04-10年,性能提升手段出现了以下趋势:
- ILP=>TLP and DLP 线程级并行和数据级并行
- 更快的单核处理器=>单芯片多处理器(多核)
- 隐含在编译器和硬件的硬件级并行技术=>显示的程序级并行
60多年计算机性能提升的两个原因:
- 构建计算机的实现技术的发展 集成电路IC、存储部件(包括RAM和DISK)、外部设备
- 计算机系统结构设计的改进 指令集、cache集成在芯片上、指令级并行技术
RISC特征:运算指令不访存,访存用LOAD/STORE指令 这是区别CISC的重要区别,指令长度不固定和有限的指令数目
1.2 计算机的分类
1.Flynn’s 分类,基于指令和数据流
SISD Single Instruction Single Memory
SIMD Single Instruction Multiple Data
在任一时钟周期,所有处理单元执行相同指令,每个处理单元能对不同数据元素进行操作 GPU
MISD 很少有,多重加密 算法对单个编码信息进行加密
MIMD 线程级或任务级并行,多核处理器
Flynn分类是抽象和粗略的
2.市场分类
个人计算机 桌面计算机 服务器 集群
嵌入式 低功耗,实时
1.3 计算机系统结构定义与计算机的设计任务
计算机系统结构的原始概念
由程序员(以机器语言编程的程序员)看见的(计算机)系统属性,即概念性结构和功能行为,以区分数据流动和控制逻辑设计的组成及物理实现。
The attributes of a [computing] system as seen by the programmer, i.e., the conceptual structure and functional behavior, as distinct from the organization of the data flows and controls the logic design, and the physical implementation.
① 主存容量与编址方式(按位、按字节、按字访问等)的确定属于 计算机系统结构。
② 为达到所定性能价格比,主存速度应多快,在逻辑结构上需采用什么措施(如多体交叉存储等)属于计算机组成。
③ 主存系统的物理实现,如存储器器件的选定、逻辑电路的设计、微组装技术的选定属于计算机实现。
AMD Opteron 64与Intel Pentium 4的指令系统相同,即两者的系统结构相同;但内部组成不同,流水线和Cache结构是完全不同的,相同的程序在两个机器上的的运行时间可能不同。
系列机:80x86到奔腾iii,保持了极好的二进制代码级的向后兼容性。缺点:为了保持软件向后兼容,要求体系结构基本不改变,妨碍了计算机体系结构的发展。
ISA指令集结构:硬件与软件之间的接口
用途:
- 开发者与硬件之间的接口
- 这代芯片与下一代的合同
接口设计
一个好的接口:
- 允许有多种实现
- 用在很多不同的方面
- 为跟高层提供方便的功能
- 允许更低层能有效实现
ISA的7个重要特征
- ISA的类型:现代通用寄存器结构,早期累加器结构
- 存储器访问:如按字节访问
- 寻址方式
- 操作数类型和大小:8位字符,32位整型数
- 操作类型:数据传输,算数/逻辑
- 控制流指令:转移,子程序调用/返回
- ISA编码:固定长度,可变长度
计算机系统结构的现代定义
在满足功能、性能和价格目标的条件下,设计、选择和互连硬件部件构成计算机
系统结构覆盖:
-
指令系统设计
-
组成
-
硬件:计算机的具体实现技术
1.4 实现技术的趋势
摩尔定律Moore Law
集成电路逻辑技术
- 晶体管密度:增加35% per year
- Die size:10%-20% per year
- 每个芯片晶体管数量:40-55%per year
半导体DRAM
- 容量:40% per year
- 访问速度:about 10% per year
磁盘技术
网络带宽
性能趋势:带宽改进优于时延
带宽增加速度和时延平方改进速度成比例
1.5 集成电路的功耗趋势
功耗对芯片的规模也提出了挑战
技术挑战:分配功率,散热,避免过热点
晶体管数量:pentium 4是386的200倍
两个概念:动态功率:开关晶体管产生的功耗
静态功率:晶体管在关闭时漏电产生的功耗
对于多核,每瓦提供更高的性能
1.6 成本的趋势
影响成本的主要因素:
- 时间,随着时间推移产出率不断提高
- 产量,意味着制造效率提高
- 商品竞争
1.7 可靠性
可靠性广义上包括可靠性、安全性和可用性
MTTF平均无故障时间
MTTR平均修复时间
MTBF平均失效间隔,两次故障间隔
提高可靠性的方法:
冗余:时间冗余和资源冗余
1.8 测量、报告和总结计算机性能
性能和执行时间互为倒数
MIPS
墙钟时间
程序开始执行到结束看钟知道的时间,测量用户感觉到的系统速度
CPU时间
not waiting for I/O,测量设计者感受到的CPU速度
CPU时间进一步分为:
用户CPU时间:花费在用户模式的时间
系统CPU时间:花费在OS的时间
吞吐量(服务器)
单位时间内完成的工作总量,测量管理员感觉到的系统性能
常用吞吐量测量:每秒处理的事务数量,如每秒服务的网页数量
通常改善了响应时间也会改善吞吐量:处理器用更快的型号替换
只改善吞吐量而不改善响应时间:在一个系统中增加额外的处理器
MIPS
用相同指令集比较两台机器,MIPS一般是公平的
选择程序评估机器性能
benchmarks
不同类型的基准测试程序
SPEC性能评价
选择一个统一的参考计算机,给出各测试程序在参考机上的执行时间
SPEC评价指标:SPEC率,Spec Mark采用SPEC率的几何平均值
1.9 计算机设计的量化原则
利用并行性
并行层次:
- 系统级:多线程,多处理器
- 指令级:流水线,超标量
- 操作级:并行加法器、组相联Cache、指令部件流水线
局部性原理
时间局部性和空间局部性
注重经常性事件
简化常用事件
- Amdahl’s定律
采用更快的执行方式所获得的系统性能提高,与这种执行方式的使用频率或占总执行时间的比例有关。
加速比=采用改进措施后计算机的性能/没有改进=没有改进措施时某任务的执行时间/采用改进措施
- CPU性能公式
性能的铁律:要直接测量使用新改进措施的改进时间是困难的
CPUtime=Instruction count * CPI * Clock cycle time
1.10 综合:性能和性价比
第二章 指令系统原理与实例
2.2 指令集系统结构的分类
不同指令集系统结构最根本的区别在于处理器内部数据的存储结构不同
存储结构:堆栈、累加器或一组寄存器,操作数可以显式或隐含指定
(1)堆栈系统结构中操作数隐含地位于栈顶
(2)累加器系统结构中的一个隐含操作数就是累加器。
**(3)通用寄存器结构系统中只能明确地指定操作数,不是寄存器就是存储器地址。
按照通用寄存器访问方式划分,有两种通用寄存器系统结构的计算机
- register-memory系统结构,一般指令可以访问存储器
- register-register或load-store系统结构,只能通过load和store指令来访问内存
2.3 存储器寻址
我们讨论的所有指令系统都是字节寻址的,都提供了字节,半字,字(32位)寻址
大端
小端模式

对齐
寻址方式:立即数通常也被认为是一种存储器寻址方式、寄存器不属于存储器寻址,相对寻址
位移量位13-16位,立即数为16位
立即寻址常用于:运算类指令、置常数到寄存器指令
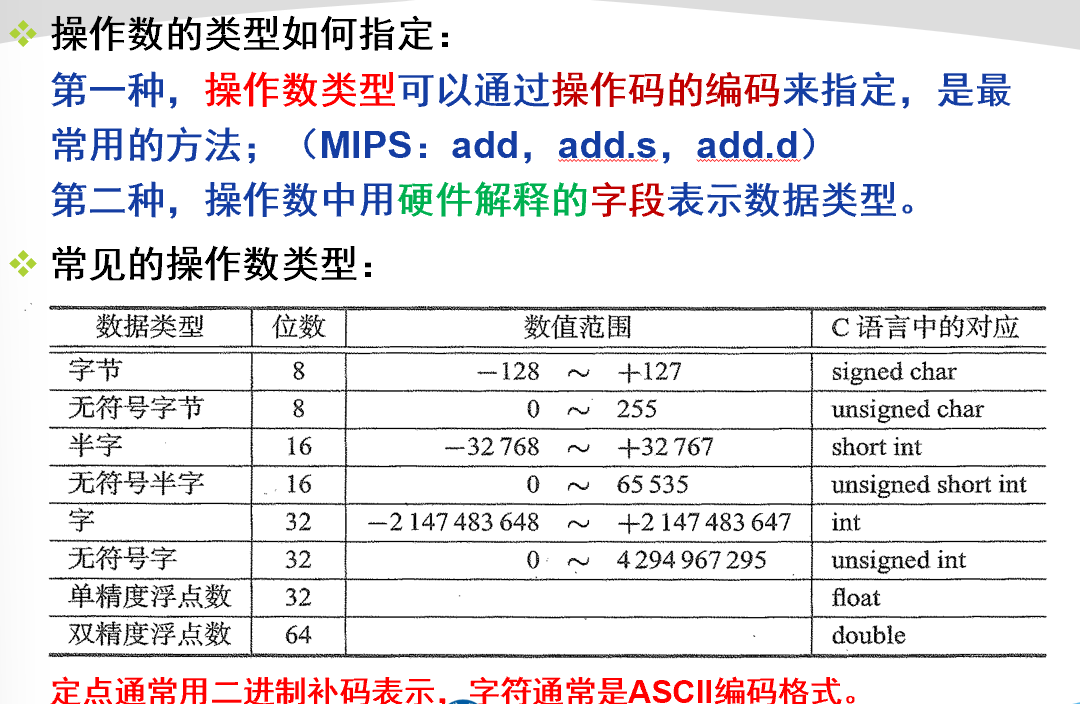
2.4 操作数的类型
操作数的类型如何指定:
操作数编码
2.5 指令系统的操作
指令系统有一条共同的规律:使用最多的是一些简单指令。
所有计算机都提供 算数和逻辑运算、load/store、控制 指令
2.6 控制流指令
条件转移、跳转、过程调用、过程返回
一般要指明转移的目标地址:
过程返回是例外,因为编译器不知道返回的地址
PC相对寻址
使用基于PC的位移量来指定目标地址
优点:
- 目标指令与当前指令离得不远,使用相对偏移地址可以缩减指令长度
- 可以载入主存任意位置,与位置无关,对于执行时才链接的程序可以减少工作量
寄存器间接跳转
编译时不知道目标位置,根据寄存器的值跳转
过程调用
保存子程序使用的寄存器:调用者保存和被调用者保存
如果两个不同的过程方法都要访问相同的全局变量,则必须使用调用者保存方法
8086中断处理子程序:调用者保存
2.7 指令系统的编码
需要在以下因素中找到一个最佳平衡点:
- 尽可能多的寄存器和寻址方式
- 寄存器字段、寻址方式字段尽量少,以缩短指令长度
- 指令长度易于流水线处理
三种常见编码方式:
- 变长 80x86 最少的位数表述程序,译码复杂,不适合流水线
- 定长 arm.mips,powerpc 译码简单,适合流水线,代码量大,执行性能高
- 混合编码
2.8 编译器的角色
编译器功能:将高级、抽象表示方式逐步转换成低级表示形式,最终达到机器目标指令代码
第三章 流水线
3.1 流水线的基本概念
3.1.1 什么是流水线
利用指令之间的并行性,实现多条指令重叠执行的技术。流水线是实现更快的的CPU的基本和关键技术 不仅是实现cpu,12级流水线用于几何变换的GPU 术语:机器周期(流水线周期)每个流水线周期从指令流水线流出一条指令。一般是一个时钟周期(有时是两个时钟周期) 吞吐量:单位时间从流水线流出的指令
我的理解:段数越多,加速越强
流水线特点
段间有流水线寄存器 流水段之间采用同步时钟控制 流水线是开发串行指令流中并行性的一种实现技术
为什么采用流水线
- 减少CPUtime
- 改进吞吐率
- 改进资源利用率
为什么不开发50段流水线
有些操作不能分为更细的逻辑实现
流水线寄存器不是免费的,要占据面积,且有延迟 机器周期>锁存器延迟+时钟偏移
流水线段数实例:
奔腾3:正在执行的指令超过20条 高ipc
太多的段数: 非常复杂 处理正在执行指令之间的相关 控制逻辑很大 简单指令执行时间过长
3.1.2 RISC 指令系统特点
- 参加运算的数据来自寄存器,结果也写入寄存器。寄存器为 32、64位
- 访存只有load和store指令
- 指令的类型较少,所有指令长度相同
- 不同指令执行的时钟周期数差别不大 这种结构可以有效简化流水线的实现
3.1.3 非流水线下RISC指令系统的实现
假定指令系统是MIPS的 一个定点子集 load、store指令:lw r1,10(r2) ALU指令: add r1,r2,r3 转移指令: beqz r1,lop
5个周期
- IF Instruction fetch cycle
- ID Instruction decode 译码+读寄存器+符号扩展
- EX Execution/effective address 计算地址/运算/branch做z=1
- MEM 读取/写入数据寄存器
- WB Wirte-Back 写结果到寄存器堆
注意:branch和store指令花费4个周期 如果我们将branch的条件判断提前到ID,则branch就只占2个周期,store和ALU指令占4周期,只有load指令占5周期
改进硬件冗余:ALU可以共享,数据和指令寄存器可以合并,因为访问发生在不同的时钟周期
3.1.3 经典5段流水线RISC处理器
CPI减少到1,因为平均每个时钟周期发射或完成一条指令,在任意时钟周期,在每个流水段正执行一条指令的部分
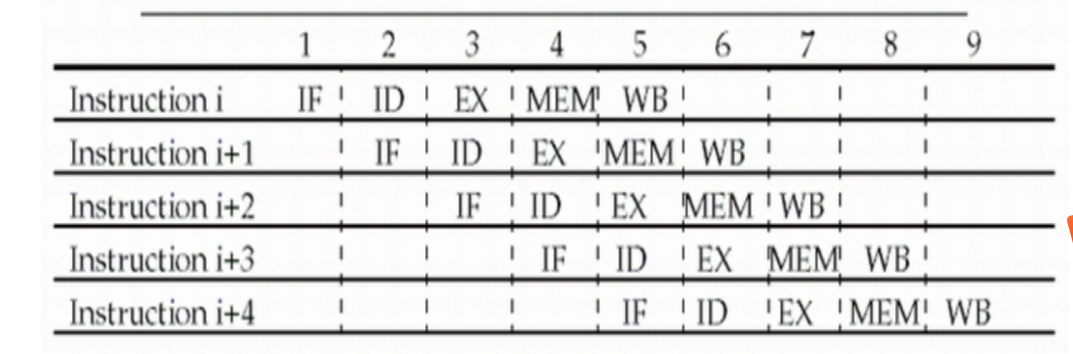 理想情况下,性能增加了5倍
理想情况下,性能增加了5倍
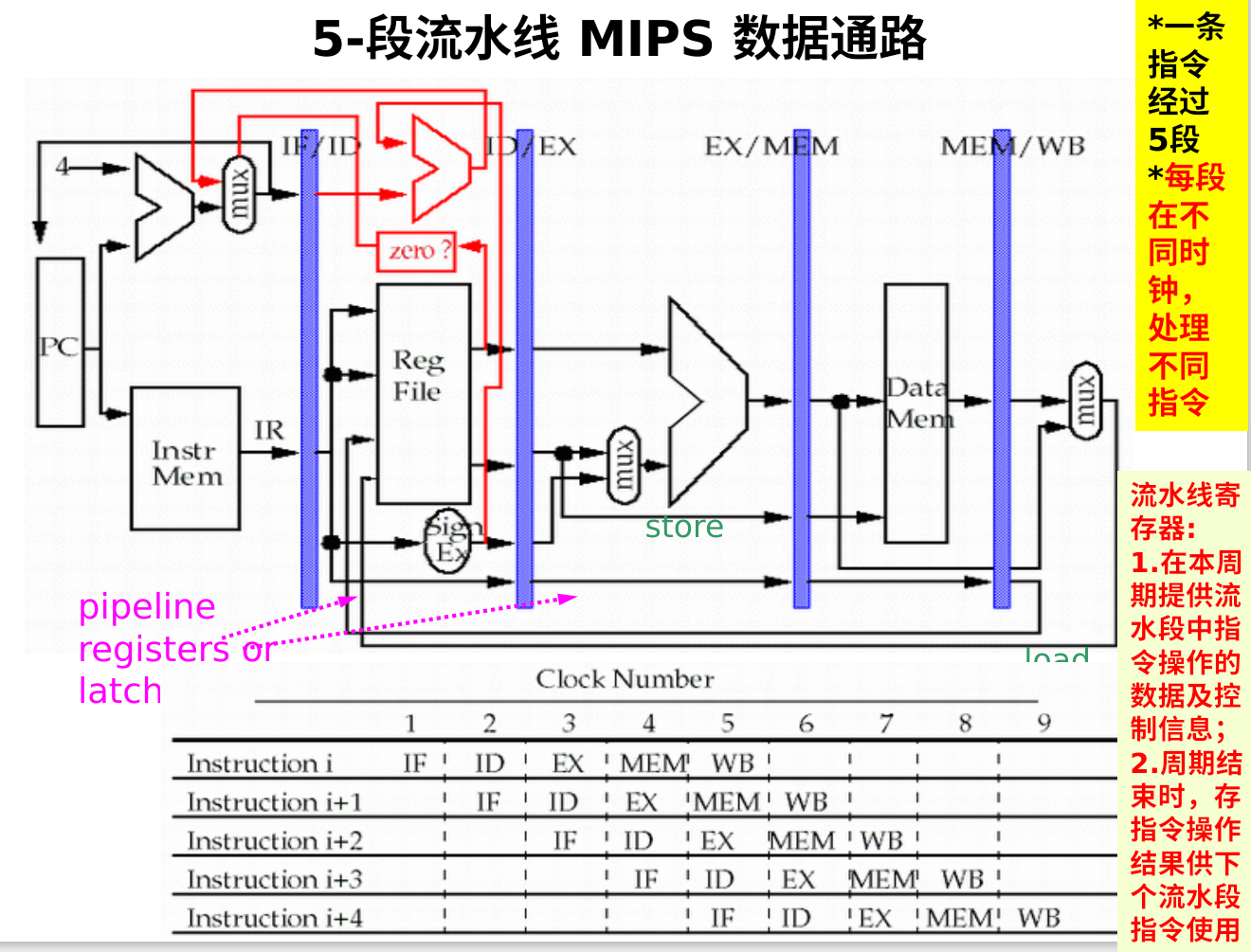
流水线如何减少执行时间?
对比不同串行实现的机器 (一个指令一个周期的机器)流水线减少周期的长度 (每条指令执行用多个时钟周期的机器)流水线减少CPI
引入流水线后出现的问题
在同一时钟周期不同操作不能使用同一数据通路资源 :结构冒险 有访问存储器冲突 设指令与数据使用同一存储器
分离的数据存储器和指令存储器
使用分开的指令cache和数据cache
如果时钟周期不变 流水线存储系统的带宽必须是非流水线的5倍
 重新设计寄存器堆资源
允许在一个时钟周期WB段先写,ID段后读
重新设计寄存器堆资源
允许在一个时钟周期WB段先写,ID段后读
- 每个时钟周期完成2个读和一个写
- 需要提供2个读端口和一个写端口
流水线寄存器必须要引入
保证处在不同段的指令不会相互干扰,任何后面段需要的值必须放在流水线寄存器中,而且复制到后的寄存器中直到不需要为止
影响流水线性能的因素
延迟
不平衡
附加开销:流水线寄存器延迟和时钟偏移
流水线冒险
3.2 流水线的主要障碍:冒险
3.2.1 冒险分类与有停顿流水线性能
冒险出现时,避免流水线上有冒险指令执行下一个流水段
串行执行不会产生冒险 阻碍流水线性能的因素:冒险
冒险总是可以用停顿解决
插入停顿 stall
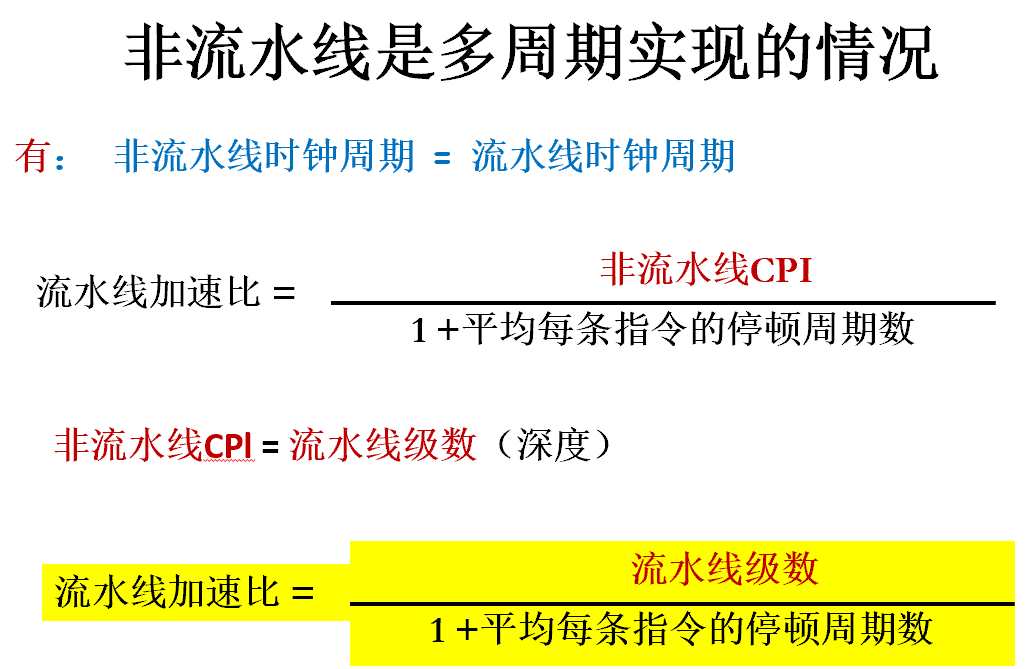
流水线CPI=理想CPI(一般是1)+平均每条指令停顿的周期数
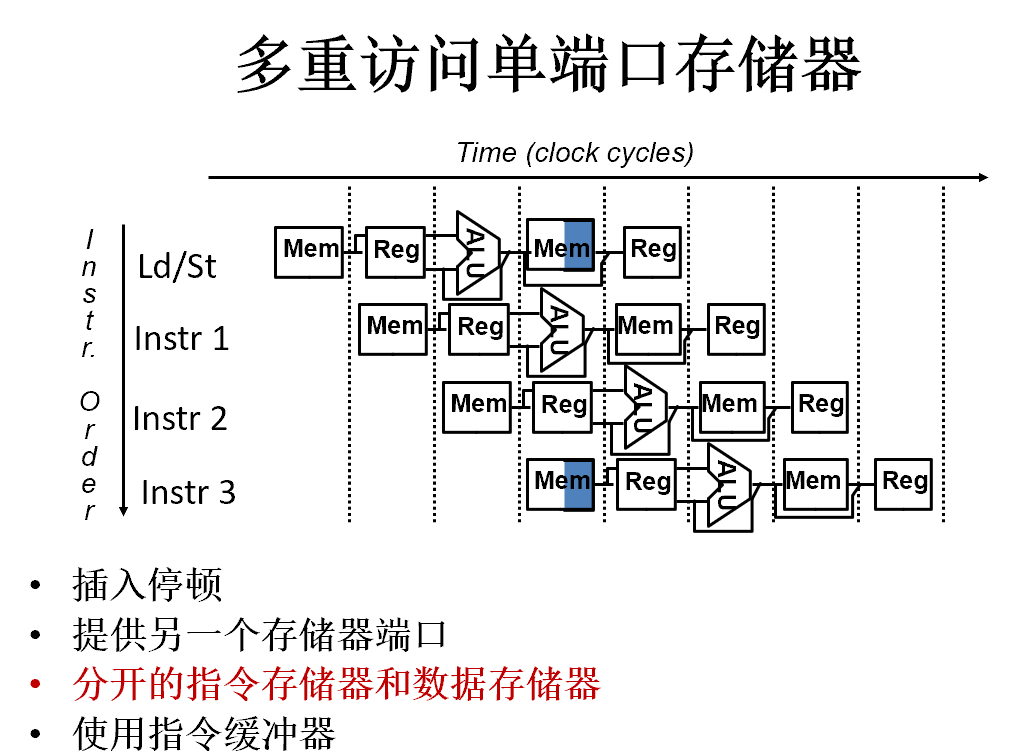
3.2.2 结构冒险
两条或多条指令想要使用同一个硬件资源
- 多重访问寄存器堆
- 多重访问存储器
- 没有或没有充分流水功能部件
解决方法:
- 简单插入一个停顿,将降低加速比
- 在一个时钟周期WB段先写,ID段后写
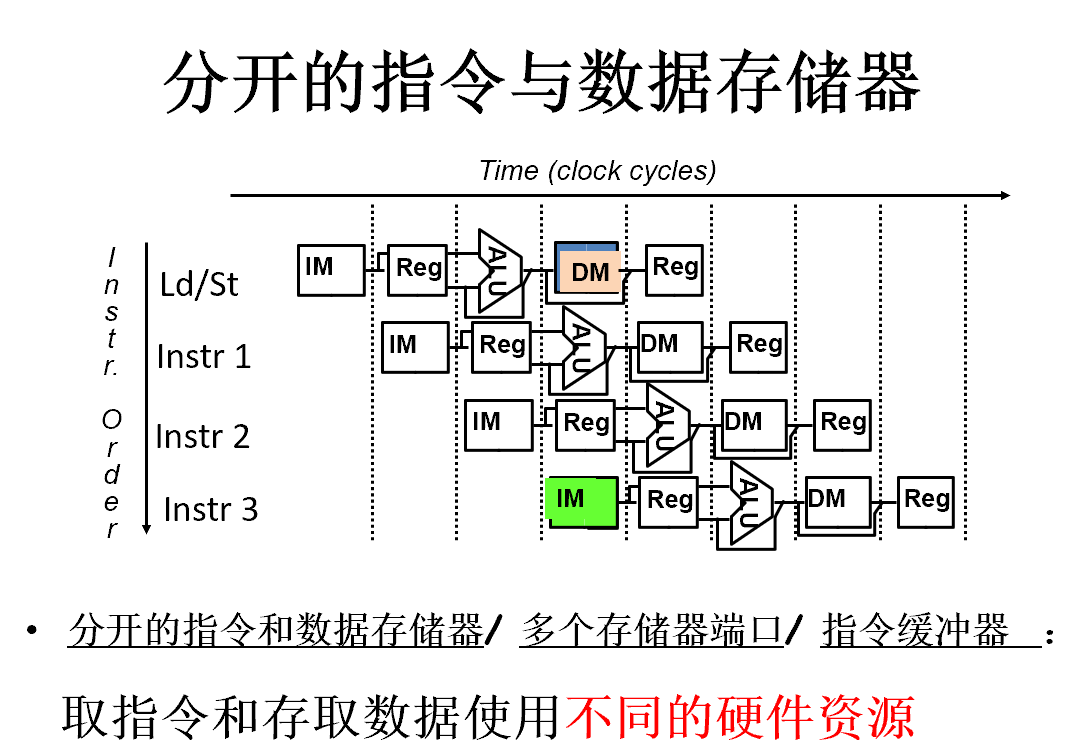
为什么允许结构冒险
减少成本,完全浮点部件需要很多逻辑门,如果结构冒险不经常发生,则消除冒险的成本就太高
减少部件延迟
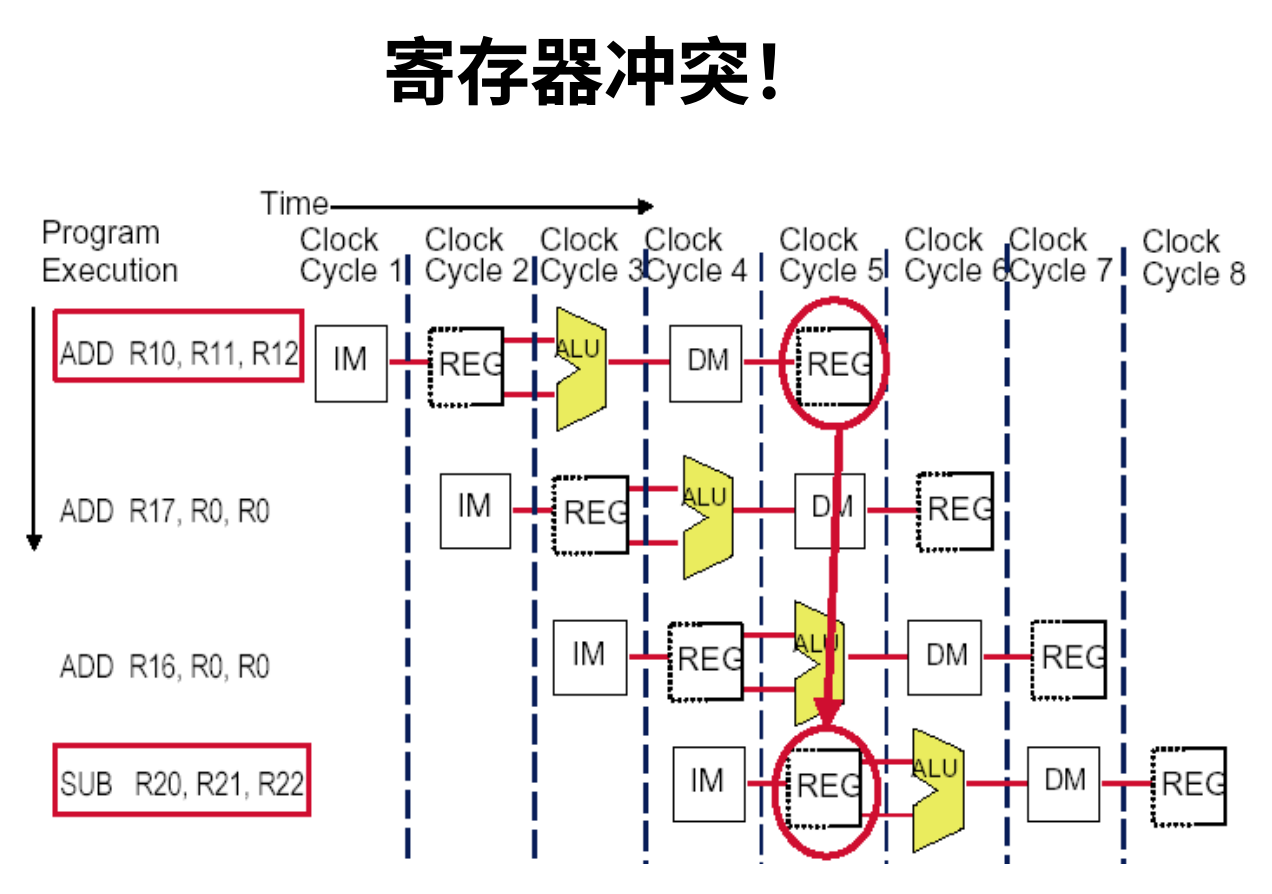
3.2.3数据冒险
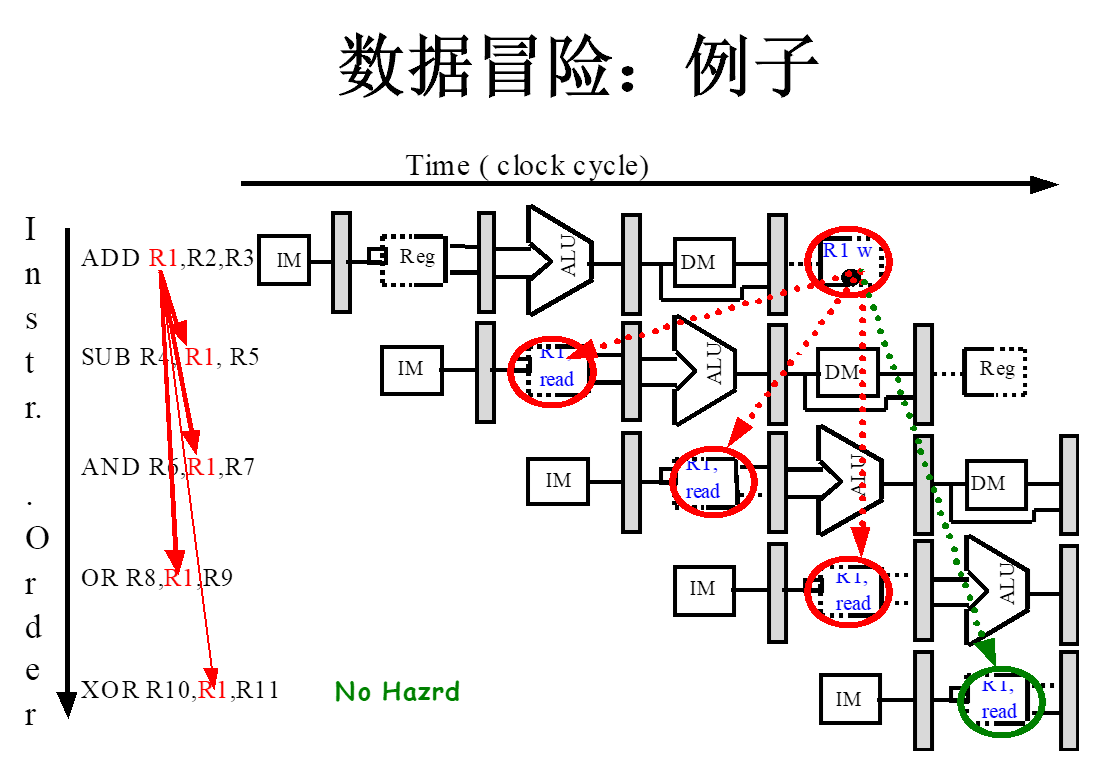
我们可以消除or r8,r1,r9这一行冒险
方法:让寄存器堆WB段先写,ID段后读
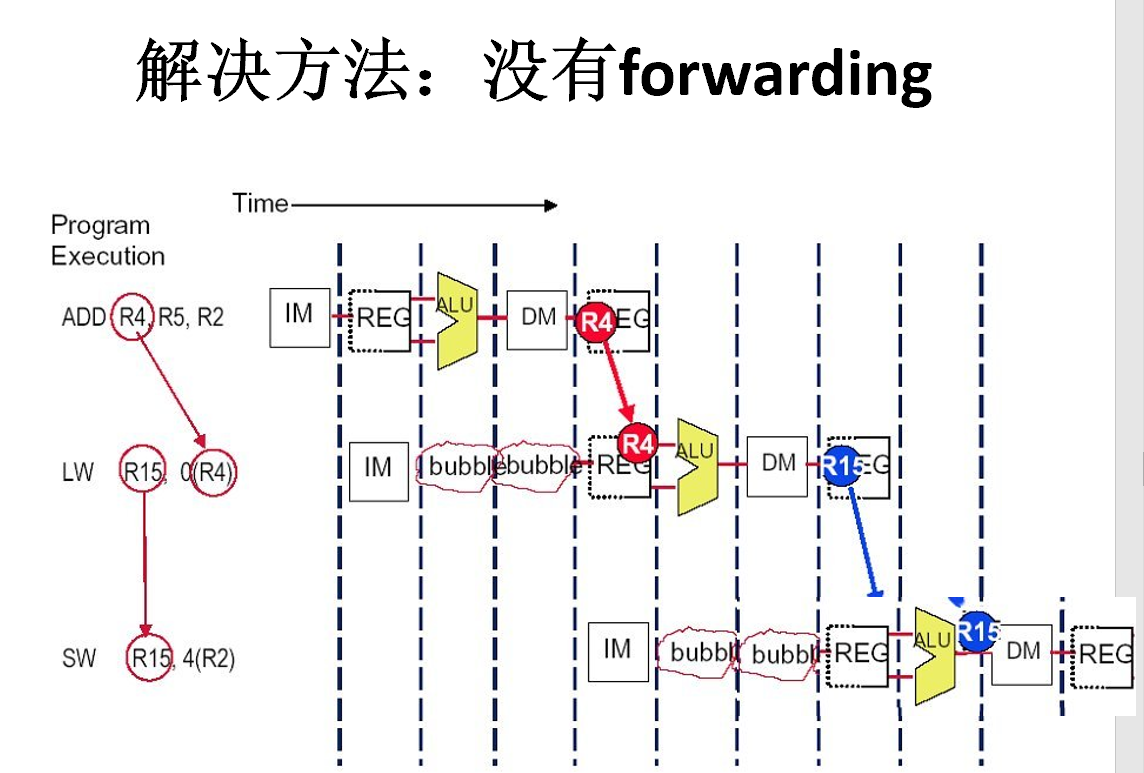
其他的冒险:停顿消除
-
编译器插入nop指令
-
增加硬件互锁
-
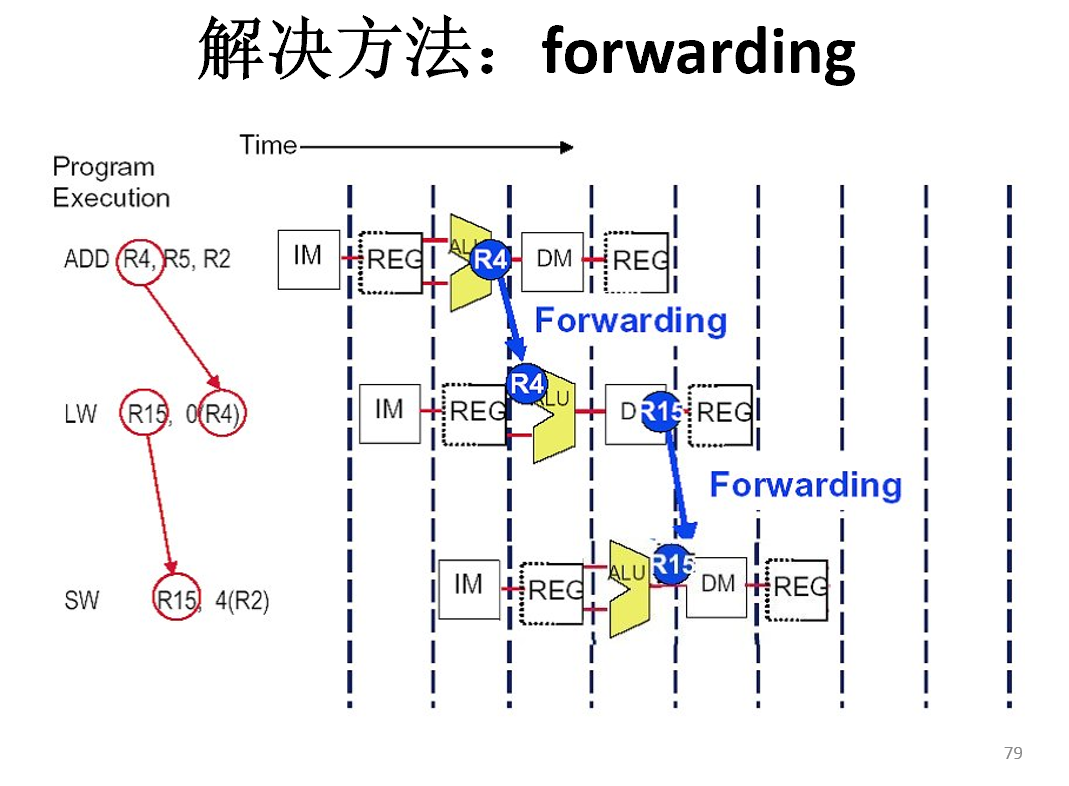
Forwarding
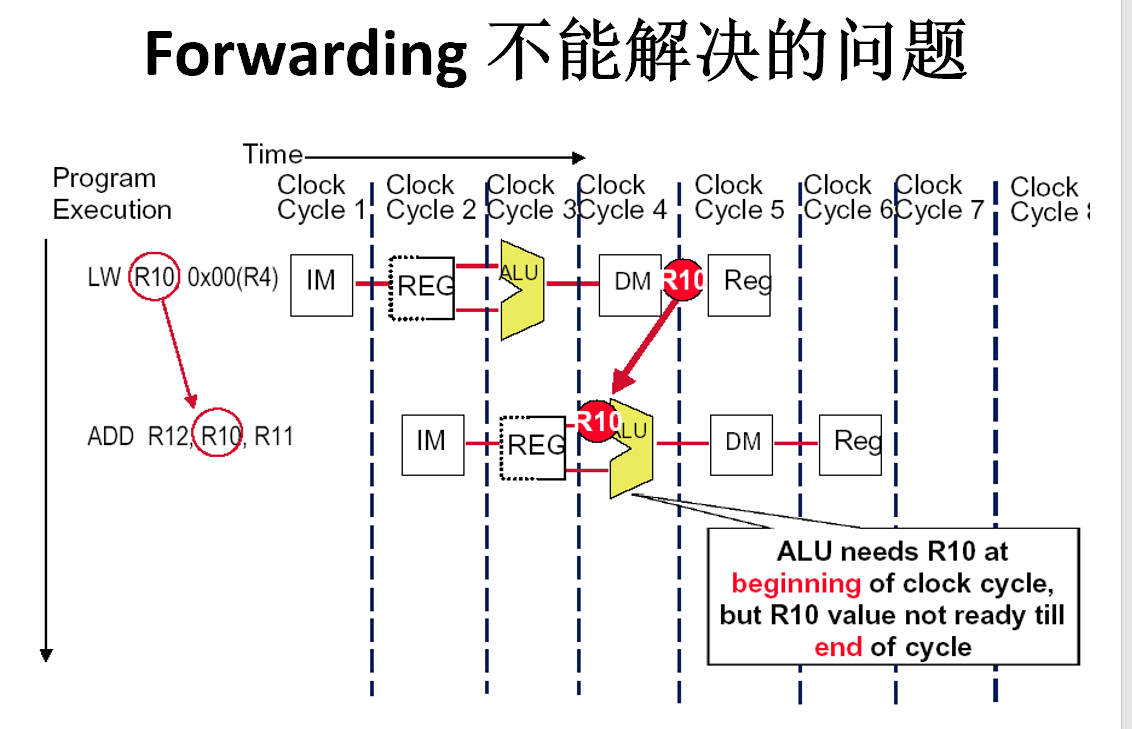
有无Forwarding的比较
3.2.4 控制冒险
在进入ID段时,转移条件和转移目标地址,不能按时提供给IF段取指令
控制冒险引起MIPS流水线的性能损失,比数据冒险大得多
处理控制冒险 4种简单解决方法
- 冻结或冲刷流水线(停顿)
- 预测转移不发生
- 预测转移发生
- 转移延迟
注意
- 以上任意一种方法都会使硬件固定
- 后3种方法,编译时会根据硬件机制和转移行为对代码进行调度,以获取最佳性能
冻结或冲刷流水线(停顿)
保持或废除转移指令之后进入流水线的指令,性能损失是固定的,不能跳过软件来减少

预测转移不发生
未选中:没有任何停顿
选中:需要重新取目标指令,引起3个stall
预测转移选中
目标地址需要提前算出来 对于经典5段流水线,性能没有提升
因此没有任何益处
转移地址提前计算,目标地址提前到ID段计算,增加一个ALU
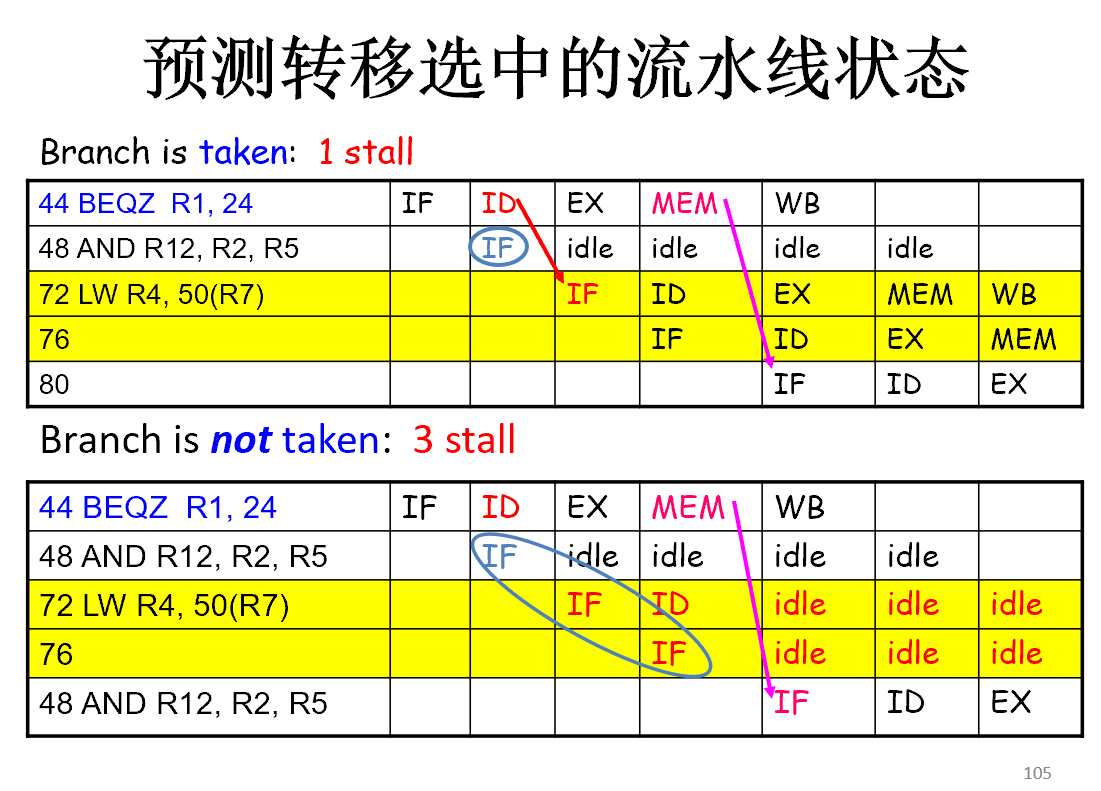
综上,预测对了可以节省时钟周期,预测错了会开始执行错误指令,要修复错误指令到没有真正执行,保证错误指令没有改变机器状态
转移延迟
将转移计算提前更早。
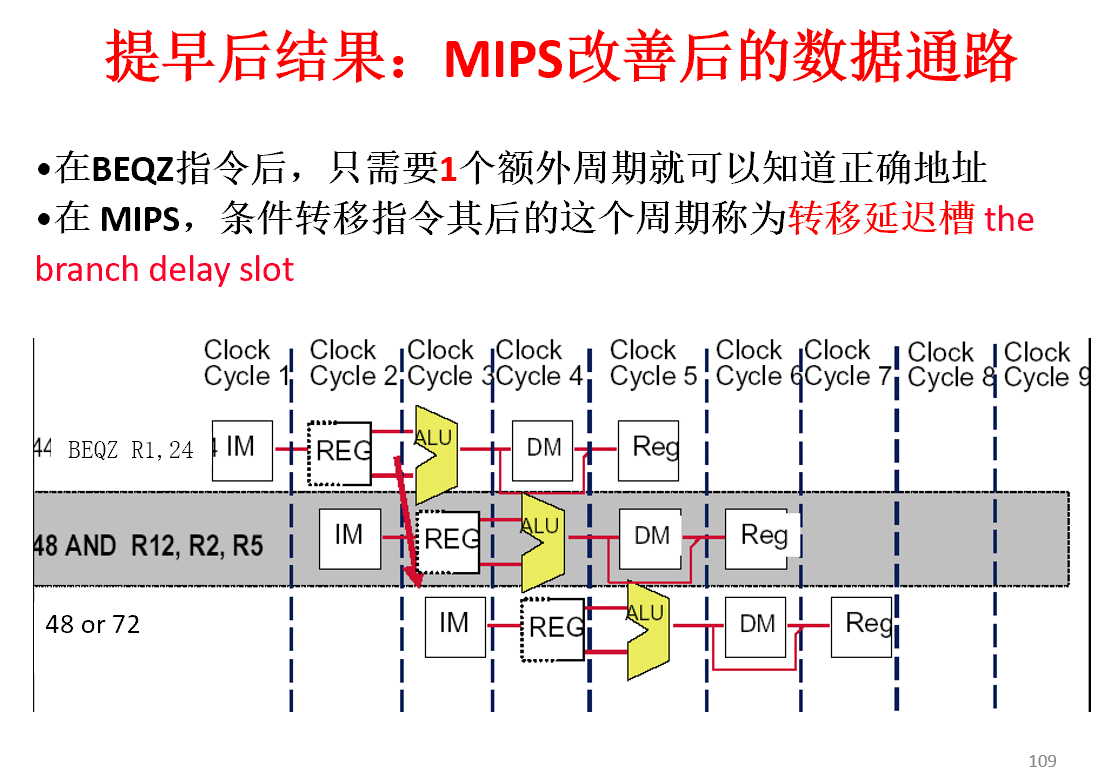



撤销功能
如果预测转移是错误的,CPU能将转移延迟槽中的指令转换为一条空操作指令
能够减少编译器选择有用指令进入转移延迟槽的复杂性
控制冒险总结
控制冒险比数据冒险引起更大的性能损失
通常,流水线越深,在时钟周期上转移损失越大
CPI更高的处理器,会付出更高的转移代价
预测机制的有效性取决于转移预测的准确性
2.3 流水线处理机及其设计
2.3.1 流水线处理机的指令系统
ALU操作类型的指令:and,or,add,sub load,store 条件转移 bne,beq branch 一共9种
指令长度32位,指令存储器和数据存储器的存储单元32位 按字寻址
ALU处理要把
2.3.2 流水线处理机的数据路径
流水线级
- IF
- ID
- EXE
- MEM
- WB
流水线寄存器
- PC
- IR
- ID/EXE
- EXE/MEM
- MEM/WB
2.3.3 流水线处理机的控制
- 有限状态机的硬布线方法
- 微程序控制方法
用软件解决冒险 运算类和Load、Store指令所需要的控制信号
一、算术操作和存储器访问控制
例子:很重要
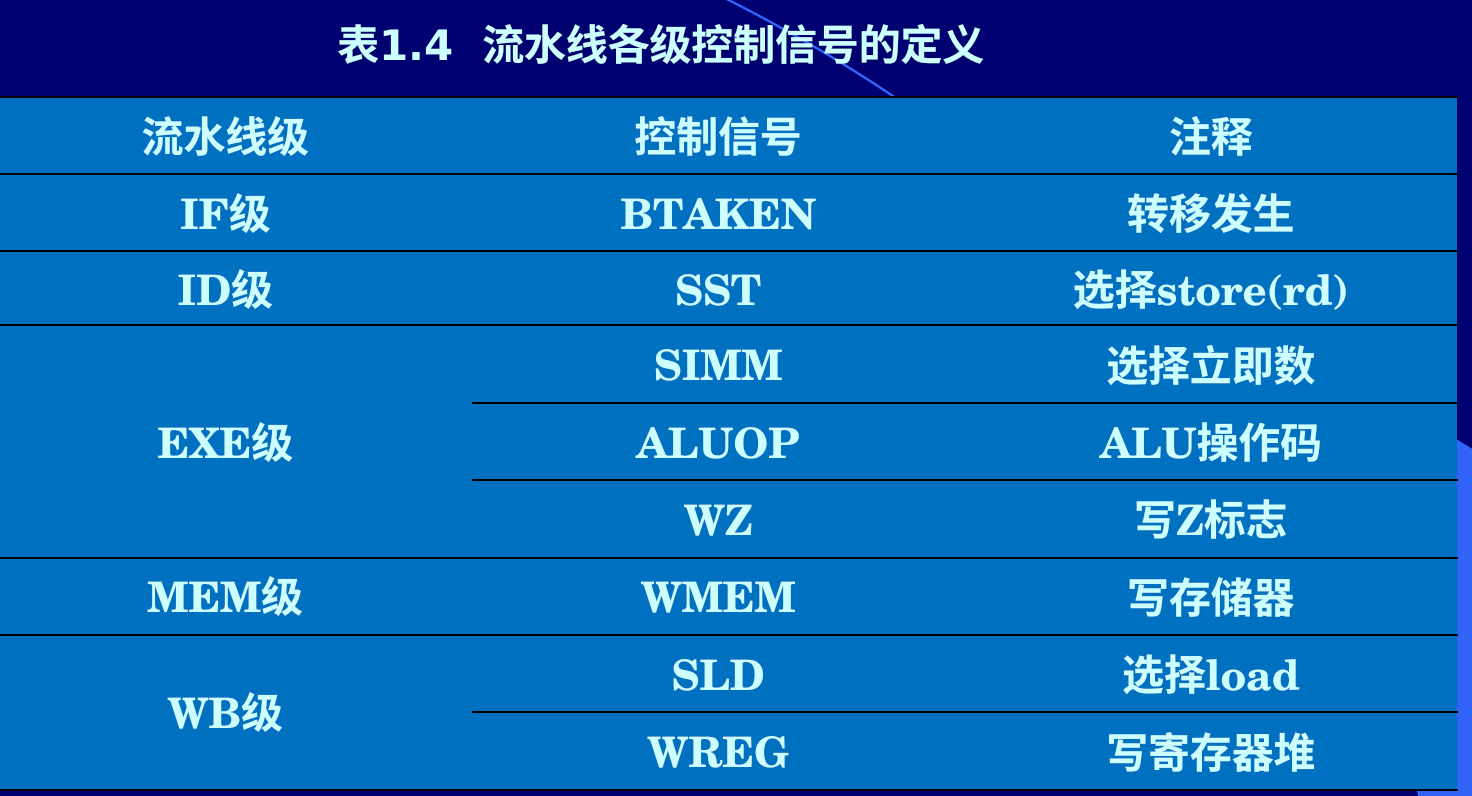
二、流水线转移指令控制
bne disp , if z ==0 ,PC=PC+disp beq disp , if z==1 ,PC=PC+disp branch disp ,PC=PC+disp
BTAKEN控制 1:转移发生 0:转移不发生 BTAKEN=branch+bne !z+beq z SST=store SIMM=andi+addi+ori+subi+load+store WZ=and+or+add+sub+andi+ori+addi+subi WMEM= store SLD= load WREG=and+or+add+sub+andi+ori+addi+subi+load ALUOP1=add+addi+sub+subi+load+store ALUOP0=or+ori_sub+subi 相对下一条指令地址转移 nop消除控制冒险
两个nop
2.3.4 结构相关及解决方法
2.3.5 数据冒险
由于流水线指令
解决方法
- 编译器插入nop
- 硬件停顿 互锁
- Forwarding 通路
互锁:硬件检测出相关,暂停流水线 增加额外硬件检测出数据相关的情况:在流水线ID级观察指令的寄存器字段,检测是否有“先写后读”冲突,如果有就暂停,没有就继续流水线操作 I2进入ID级,比较ID_rs1 == EXE_rd?或 ID_rs2 == EXE_rd? I3进入ID级,与EXE级I2指令的rd比较同时与MEM级I1指令的rd比较
上述分析表明,一条指令进入流水线ID级, 检测与前面指令可能有数据相关的基本条件是: (ID_rs1 == EXE_ rd )+(ID_rs1 == MEM_ rd) + (ID_rs2 == EXE_rd )+ (ID_rs2 == MEM_rd)
其他条件 1.EXE级和MEM级指令的WREG信号需参与检测(以区分是写目的寄存器rd,还是store指令中的rd。store使用rd,但不写rd。) 2.ID级指令的源寄存器号rs2与立即数部分重叠,而立即数不会出现相关的。(用操作码区分) 3.ID级的指令不能是转移指令,转移指令不需要判数据相关(但要判断控制相关)。(用操作码区分)
一条指令的两个源操作数都可能与前面指令的目的操作数相关,因此总的数据相关DEPEN: DEPEN=(ID_rs1= =EXE_rd)(EXE_WREG= =1)(ID_rs1IsReg)+ (ID_rs1= =MEM_rd)(MEM_WREG= =1)(ID_rs1IsReg)+ (ID_rs2= =EXE_rd)(EXE_WREG= =1)(ID_rs2IsReg)+ (ID_rd= =EXE_rd)(EXE_WREG= =1)(store) + (ID_rs2= =MEM_rd)(MEM_WREG= =1)(ID_rs2IsReg)+ (ID_rd= =MEM_rd)(MEM_WREG= =1)(store) 解释: ID_rs1IsReg=and+andi+or+ori+add+addi+sub+subi+load+store ID_rs2IsReg=and+or+add+sub (排除立即数运算指令、load和转移指令)
(EXE_WREG= =1)表示EXE级指令的rd确实是目的寄存器,排除store指令。 (ID_rs1IsReg)条件是为了排除转移指令。
为了缩写前面的式子,总的数据相关DEPEN由A_DEPEN 和 B_DEPEN两部分组成:
DEPEN=A_DEPEN + B_DEPEN
内部前推
5
5.5
第四种缺失代价减少技术 合并写缓冲 方法:用多个字代替一个字
第五种缺失代价减少技术 牺牲缓存victim cache 牺牲缓存是一个小的全相联cache,它存放几个最近被替换出的块 在发生缺失要访问下一级存储器之前,先检查牺牲cache
5.6 利用并行技术减少Cache代价缺失率
非阻塞cache减少cache缺失等待
![[Pasted image 20220505103603.png]]
编译器控制的预取 需要硬件实现 编译器插入预取指令请求数据 有两种预取方式:
- 捆绑预取,请求预取的值直接装入寄存器
- 非捆绑预取,将数据预取到cache
5.7 命中时间减少技术
在cache索引时避免地址转换 传统物理地址cache存在的问题:地址转换 访问页表,访问内存
变换旁路缓冲器TLBs 一种快速地址转换,存放最近的页表项
踪迹cache 踪迹cache:块中是动态指令序列,而不是限制指令在一个静态cache块中。 cache块中包含了由cpu确定的要执行指令的动态踪迹,而不是仅由存储器确定的静态指令序列